Motivation
One of the biggest challenges during designing new neural network architectures is time. During real-world workflows, one often trains many different neural networks during the experimentation and design process. This is a wasteful process in which each new model is trained from scratch.
In a typical workflow, one trains multiple models, with each model designed to improve upon the previous model in some way. As a result, this iterative design process relies on fully training and evaluating the innovations from the previous step (design) from scratch. This makes the whole designing process slow due to the latency of evaluating whether each change to the model caused an improvement or not.
This is where the Net2Net procedure come in. It’s (in my opinion) a really cool yet simple method to address the above problem to some extent.
Net2Net Procedure
The Net2Net strategy involves initializing the student network (the new model) to represent the same function as the teacher (the previous model), then continue training the student network by normal means. What this means is that, before further training the student network, for every input, it will give the same output (label) as the teacher network even though its architecture may be quite different from the teacher network.
Mathematically, suppose that the teacher network is represented by a function y = f(x; θ) where x is the input to the network, y is the output of the network, and θ is the parameters of the network. The Net2Net strategy is to choose a new set of parameters θ’ for the student network g(x; θ’) such that
∀x, f(x; θ) = g(x; θ’)
There are two ways of using Net2Net: Increase the width or the depth of the network.
Net2WiderNet

This allows a layer to be replaced with a wider layer, meaning a layer that has more units. For convolution architectures, this means the layers will have more convolution channels.
Suppose that layer i and layer i + 1 are both fully connected layers, and layer i uses an elementwise non-linearity. To widen layer i, replace 



New weight matrices 
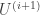



Here, the first n columns of 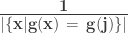
The random mapping function g can be defined as, g : {1, 2, · · · , t} → {1, 2, · · · , n}, that satisfies:

The above is just one of the many ways to define the function g. These functions are subject to constraints defined by the computation graph of the model, as care needs to be taken to ensure that the remapping function does, in fact, result in function preservation. One example of a constraint imposed by the batch normalization layer. The layer involves a linear transformation (shifting) and also elementwise multiplication (scaling) by learned parameters. The random remapping for the multiplication parameters must match the random remapping for the weight matrix. Otherwise, a new unit could be generated that uses the weight vector for pre-existing unit i but is scaled by the multiplication parameter for unit j. The new unit would not implement the same function as the old unit i or as the old unit j (in the teacher network), which is not the desired result.
Net2DeeperNet
This allows us to transform an existing net into a deeper one. A layer 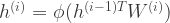

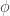

The above method of Net2DeeperNet is a specific case of factorizing a layer in a network. It factorizes a layer 

How Effective is Net2Net?
Due to the function preserving method used, the new larger network (student network), performs just as well as the original network (teacher network) instead of having to go through a period of low performance.
Also, Networks trained using Net2Net converge faster to the same accuracy as networks initialized randomly. Though, one thing to note is that the final accuracy is independent of the training procedure and only dependent on the size of the network.
Graphs showing the results of experiments performed by the authors of the paper show how much beneficial it is to train using Net2Net when designing new architectures and experimenting.
Experiment with Net2WiderNet:


“Random pad”: The network is widened by adding new units with random weights, rather than by replicating units to perform function preserving initialization. This operation is implemented by padding the pre-existing weight matrices with additional random values.
Experiment with Net2DeeperNet:


Another merit is that, while training the student network no special changes have to be made in the hyperparameters. Nearly all of the hyperparameters that are typically used to train a network from scratch can be used to train a network with Net2Net. This makes Net2Net very simple to use. However, using an initial learning rate of 0.1 times that of the initial learning rate of the teacher network proves to be more effective. An intuition to why this is advised is because the training of the student network can be considered as just the further training of the original network, and as training progresses the learning rate is usually decreased to allow the network to converge at the optimal global minima.
Improvements to be Made
While Net2Net is a really innovative method that works really well, it has its limitations. First of all, Net2Net can only be used to increase the width and depth of the network. Using Net2Net you cannot make changes to the kernel sizes in a CNN. Secondly, while increasing the depth of the network, Net2Net is restricted to using identity mappings. A step upward would be to factorize the original weight matrix into non-identity factors. Thirdly, Net2Net can only work for idempotent activation functions (an idempotent function ϕ is defined to satisfy ϕ ◦ ϕ = ϕ, such as ReLU). This limits the applications of using Net2Net.
Original Paper: Net2Net: Accelerating Learning via Knowledge Transfer
