Motivation
What if you want to do some real-time face detection/recognition using a deep learning system running on a pair of glasses? What if you want your alarm clock to be able to record and analyze your sleep and conditions around you and come up with the most optimal way of waking you up each day? Overall, the question is, can you efficiently run a deep neural network under the hardware limitations of such devices, such as limited power, memory space, size, etc?
This is where Binarised Neural Networks (BNNs) – neural networks with binary weights and activations, come into action. BNNs are extremely compact, yet powerful. Generally, Deep Neural Networks (DNNs) require powerful GPUs and memory for training and storing the trained model but small devices cannot supply such luxuries. A BNN is defined by all binary numbers; hidden unit outputs, weights, biases, and activations. First, binaries are cheap to store. Comparing a 32-bit floating-point representation (used in most DNNs) with a single bit, it’s obvious that the single bit representation uses 1/32 of the space required by the 32-bit representation. Second, binaries are cheaper to compute.
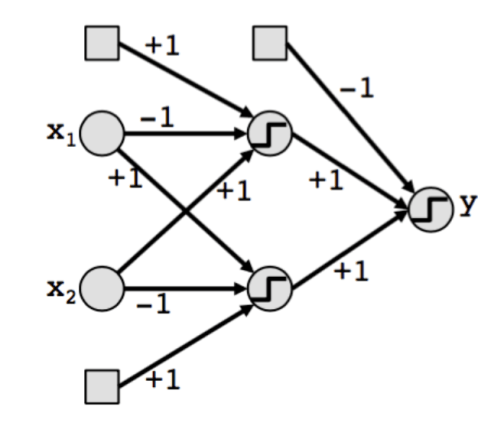
The Architecture
The architecture of a BNN is similar to any typical DNN architecture, except, everything is binarized to either +1 or -1.

Binarization
In order to transform the real valued variables into these two values, two binarization functions can be used. The first function, which is deterministic is:
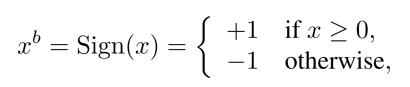
where 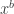
The second binarization function is stochastic (probabilistic):

where σ is the “hard sigmoid” function:
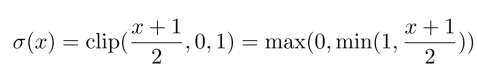
The stochastic binarization is better than the Sign function but is harder to implement. As a result, the deterministic Sign function is used more often.
Gradient Computation
Although a BNN training method uses binary (+1 or -1) weights and activations to compute the parameters gradients, the real-valued gradients of the weights are accumulated in real-valued variables.
The reason for using real-valued gradient flow is because it is required for Stochastic Gradient Descent to work properly. SGD explores the space of parameters in small and noisy steps, and that noise is averaged out by the stochastic gradient contributions accumulated in each weight. Therefore, it is important to keep sufficient resolution for these accumulators, and hence use more than 1-bit. This method of training can be seen as a variant of Dropout, in which instead of setting some of the activations to zero when computing the parameters gradients, both the activation and the weights are binarized.
Gradient Propagation
One problem comes up while performing backpropagation. The derivative of the binarization functions is zero almost everywhere. As a result, the exact gradient of the cost function w.r.t. the quantities before the binarization step would be zero. This would render SGD useless and our network would never get trained!
To solve this, “straight-through estimator” is used. This is a method of getting the gradient of threshold operations (such as the binarization functions) in neural networks. You just estimate that the incoming gradient to a threshold operation is equal to the outgoing gradient (on average you will get the right result). In other words, while doing backpropagation, the binarization functions get treated as if they were identity mappings.
To train a BNN, the above method is used with a small modification to take into account the saturation effect. Consider the sign function quantization:
![]()
and assume that an estimator 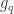
![]()
Note, that this preserves the gradient’s information and cancels the gradient when r is too large. Not canceling the gradient when r is too large significantly worsens the performance. This acts as a gate and prevents neurons with large activations (|r| > 1) to be updated.

Parameter Update
While updating the weights, the following is done:
- Each real valued weight,
, is constrained to remain between -1 and +1. If a weight update brings
.
- The new updated binary weights are then calculated as
So Why Are BNNs so Efficient?
BNNs have a very efficient forward pass. Power is one of the biggest constraints on the performance of DNNs. Also, memory access consumes more energy than arithmetic operation. As a result, higher memory size means more energy consumption. In comparison with 32-bit DNNs, BNNs require 32 times smaller memory size and 32 times fewer memory accesses. This reduces the energy consumption drastically (even more than 32 times).
When using a ConvNet architecture with binary weights, the number of distinct unique filters are limited. If the dimension of a filter is k × k, then there are only 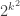
Conclusion
BNNs, while being computationally cheap and also small in size are still able to perform with high accuracy. They are the go to networks for running neural networks on very small devices.
Original Paper: Binarized Neural Networks: Training Neural Networks with Weights and Activations Constrained to +1 or −1

This is really awesome and helpful I took reference from this blog and created a video.
LikeLiked by 1 person