
This is the only paper I know of that references a meme! Not only this but this model also became the state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14).
Problems the Paper Addressed
To create a deep network with high accuracy while keeping computation low. Google being a company wanted something that can be used practically in the real world and not be shelved as an academic wonder for decades. Winning ImageNet competition is just and added extra bonus!
The Architecture
First let’s look at the inception module, which is the heart of the GoogLeNet Architecture.
Inception Module
While doing convolutions it is important to decide what type of convolution to do at each layer: Do you want a 3 × 3? Or a 5 × 5? You have to make this decision for each and every layer. The best path is to somehow choose the best layer combination for the whole network! But there is no method to do this! Or is there?
This is where this innovative architecture, the Inception Module, comes in! Instead of us having to scratch out head and pull our hairs, deciding the type of covolution to use, you use all of them and let the network decide for itself the optimal configuration! You do this by doing each convolution in parallel on the same input, with same padding i.e. spatial dimensions of output is same as the input, and concatenating the feature maps from each convolutions into one big feature map. This big feature map is fed as input to the next inception module.
In theory you can have as many filter sizes as possible, but the Inception Architecture is restricted to filter sizes 1 × 1, 3 × 3 and 5 × 5. The small filters help capture the local details and features whereas spread out features of higher abstraction are captured by the larger filters. A 3 × 3 max pooling is also added to the Inception architecture, because, why not? Historically, it has been found that pooling layers make the network work better, so might as well add them!
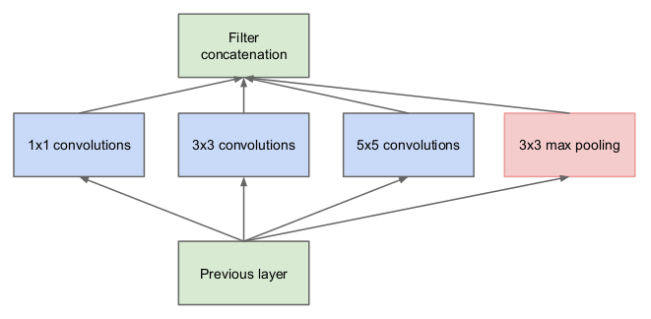
One big problem with the above naive form of the inception module is that the large convolution are computationally expensive.
Let’s just examine what the 5×5 convolution would be computationally:

In the above convolution, there would be,
(5²)(192)(32)(28²) = 120,422,400 operations
This is a lot of computation!
Something must be done to bring down this number! A method to reduce the number of computation is Dimensionality Reduction. This involves convolutions with 1 × 1 filters before convolutions with bigger filters.
Let’s look at the 5 × 5 convolution with dimensionality reduction:
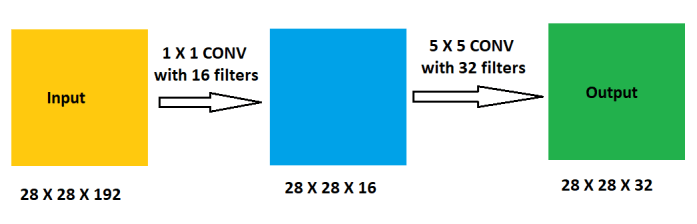
In the above there would be,
(1²)(192)(16)(28²) = 2,408,448 operations for the 1 × 1 convolution and,
(5²)(16)(32)(28²) = 10,035,200 operations for the 5 × 5 convolution.
In total there will be 2,408,448 + 10,035,200 = 12,443,648 operations. This is a reduction in the total amount of computation by about a factor of 10!
Not only do these 1 × 1 convolutions help reduce the dimensions but also had the extra benefit of adding an extra non-linearity, thus, making the model map even more complex functions.
Similar is the case with the 3 × 3 layer. Also, pooling layers preserve the depth. As a result, the depth keeps on increasing rapidly. To prevent this a 1 × 1 conv. layer is added after the 3 × 3 max pooling layer in the inception module, with a lower number of filters to reduce the depth of the output feature map.
One thing to note is that the output spatial dimension of an Inception Module matches that of the input to it i.e. only the depth gets effected.
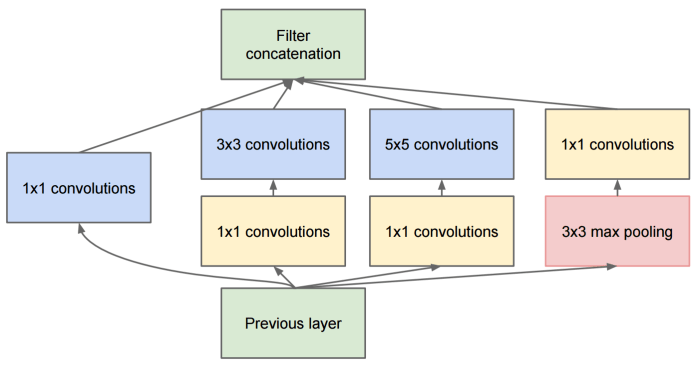
This wraps up details of the Inception module. Now let’s look at the GoogLeNet Architecture which uses multiple such inception modules.
GoogLeNet Architecture
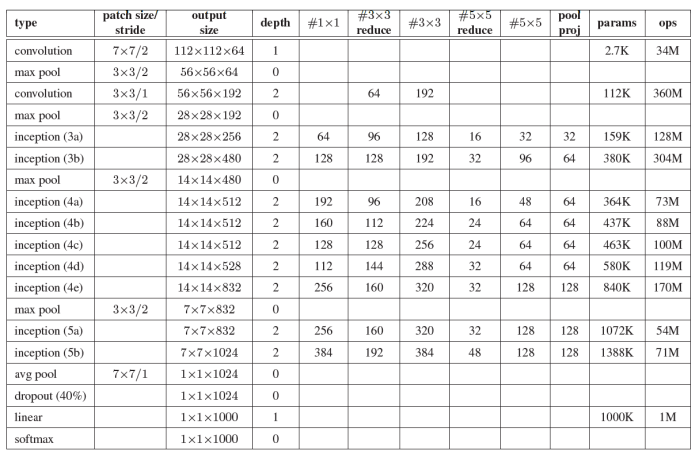
In the above “#3 × 3 reduce” and “#5 × 5 reduce” stands for the number of 1 × 1 filters in the reduction layer used before the 3 × 3 and 5 × 5 convolutions. One can see the number of 1 × 1 filters in the projection layer after the built-in max-pooling in the “pool proj” column. All these reduction/ projection layers use rectified linear (ReLU) activation. I suggest you carefully read the above table, especially the first three columns.
The network is 22 layers deep. The initial layers are simple convolution layers. After that there are multiple blocks of inception modules with layers of max pooling following some of the blocks. The spatial dimensions get affected by these max pooling layers only. Another interesting addition to the architecture is to change the second last fully-connected layer with an average pooling layer. This layer spatially averages the feature map, converting 7 × 7 × 1024 input to 1 × 1 × 1024. Doing not only reduces the computation and the number of parameters, by a factor of 49, of the network but also improves the accuracy of the model, improving top-1 accuracy by 0.6%. This average pooling layer is finally followed by a normal fully-connected layer with 1000 neurons (and 1024 × 1000 parameters), for the 1000 ImageNet classes.
GoogLeNet Training
During training, to address the vanishing gradient problem, special extra structures are added to the network (these are removed during testing). These are auxiliary classifiers attached to intermediate layers which serve two purposes:
- Doing this makes the layers in the middle of the network more discriminative and thus make them able to extract better features.
- All the losses from each classifier gets added up, taking contribution from the auxiliary classifier lower than the main one, during training. The gradient from the main classifier which would have otherwise become very small, and thus slowing training, by time it reached the lower initial layers, receives gradient from the auxiliary classifiers and thus the net gradient becomes big enough to allow training to progress
The exact structure of the extra network on the side, including the auxiliary classifier, is as follows:
- An average pooling layer with 5 × 5 filter size and stride 3, resulting in an 4 × 4 × 512 output for the (4a), and 4 × 4 × 528 for the (4d) stage.
- A 1 × 1 convolution with 128 filters for dimension reduction and rectified linear activation.
- A fully connected layer with 1024 units and rectified linear activation.
- A dropout layer with 70% ratio of dropped outputs.
- A linear layer with softmax loss as the classifier (predicting the same 1000 classes as the main classifier, but removed at inference time).
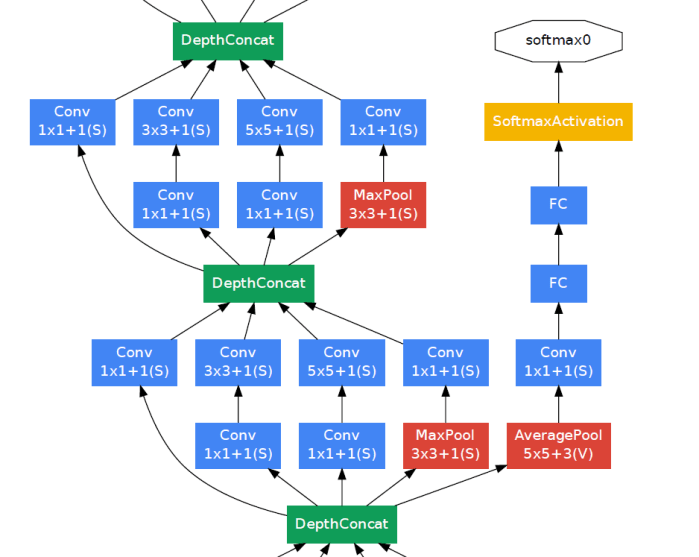
You can think of these as small child networks along with the one big parent network.
Training was done using asynchronous stochastic gradient descent with 0.9 momentum. The learning rate is decrease by 4% every 8 epochs regardless of whether the accuracy has plateaued or not (as is usually done).
Conclusion
One of the main driving force for this work was to make sure conv. nets don’t remain academic wonders but are practically usable in the daily world. It did achieve this really well. The number of parameters, and hence size, is considerably less than many well performing networks like AlexNet and VGGNet but without any sacrifice in accuracy! Though, due to the complex architecture of GoogLeNet (Inception Module), many people tend to shy away from using it and pick the simple and uniform VGGNet for small tests.
Original Paper: Going Deeper with Convolutions
Implementation of Inception Module: https://github.com/Natsu6767/Inception-Module-Tensorflow

Thank you very much!
Best explanation on the internet.
LikeLike
Thank u Mohit Sir, very nice explanation of GoogleNet
LikeLiked by 1 person
Glad that you found it useful.
LikeLike