
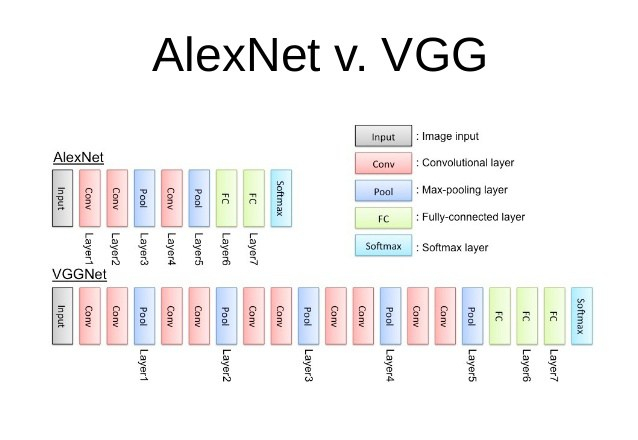
This is probably the most simple looking and straightforward network ever. Simple yet powerful; wining the ImageNet 2014 Localisation competition and coming second in the Classification track!
Problems the Paper Addressed
To show that making a network deeper improves its accuracy and also multiple small filters are better than a single large filter when both have same receptive field areas on the input image.
VGGNet Architecture
The architecture of VGGNet is very simple. The following tables from the paper beautifully summarizes the whole architecture for different variations of the network:
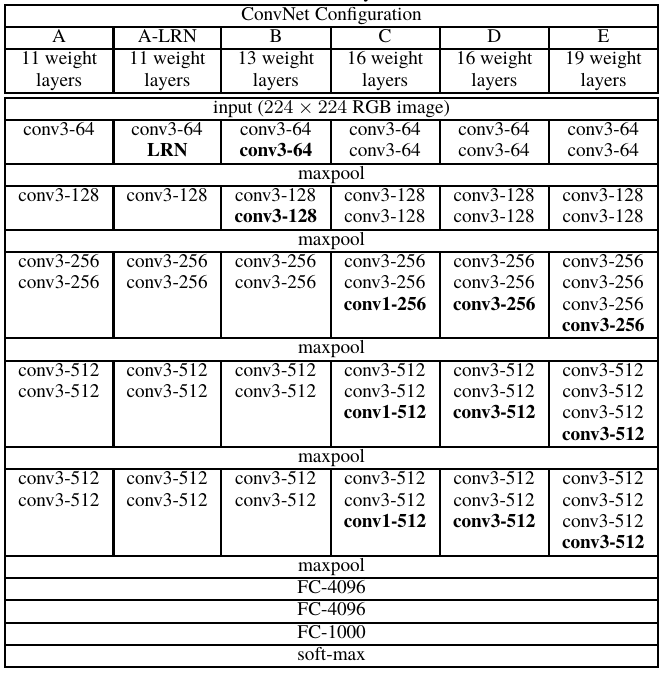

In the above, the convolutional layer parameters are denoted as “conv〈filter size〉-〈number of channels〉”. Therefore, conv3-64 represents a convolutonal layer which uses 64 filters of size 3 × 3. The stride size is 1 for all convolutions. Also, all the inputs to conv layers are appropriately padded such that after the convolution step the spatial dimension of the output is same as the input. Only the pooling layers are responsible for changing the spatial dimensions!
Instead of using large filter sizes with large strides (such as in AlexNet), VGGNet uses small 3 × 3 filter sizes with stride 1 throughout the whole net. A stack of two 3 × 3 conv. layers (without spatial pooling) has an effective receptive field of one 5 × 5 conv. layer; and three such conv. layers have an effective receptive field of one 7 × 7 conv. layer. As a result, by using multiple small filter we are not loosing any information (in terms of receptive field area). But using small multiple filters offers many advantages!
Let’s compare three 3 × 3 conv. layers and one 7 × 7 conv. layer. Both have the same receptive field. First, using the stack of 3 × 3 conv. layers incorporates three non-linear rectification layers instead of a single one in 7 × 7 conv. layer. This makes the decision function more dicriminative and hence learn more complex features. This allows the model to create a better mapping from the images to the labels. Second, the parameters decrease using the stack of 3 × 3 conv. layers. Assuming both the input and output have C channels, the stack of 3 × 3 is parametrised by 3×(3²C²) = 27C² weights whereas the 7 × 7 will require 1×(7²C²) = 49C² weights, which is 81% more! Using 3 × 3 conv. layers decreases the size of the model on memory and also acts as a sort of regularisation, making the network less prone to overfitting.
In the configuration C of the VGGNet (in the table), 1 × 1 conv. layers are also used. This is just a way to add an extra non-linearity without affecting the receptive fields of the conv. layers, i.e. it maintains the current spatial resolution as well as the receptive field area. An extra non-linearity allows the model to learn more complex representations and features.
All max-pooling layers use a 2 × 2 filter with stride 2. This results in the reduction of spatial dimensions by a factor of 2. A ReLU non-linearity is applied to every output of the conv. layers and the fully-connected layers.
Training
The training is carried out by optimising the multinomial logistic regression objective using mini-batch gradient descent with batch size of 256, momentum set to 0.9 and using L2 regularisation. Dropout is only applied to the first two fully-connected layers with dropout probability set to 0.5. The initial learning rate is 0.01 and is decreased by a factor of 10 every time the validation set accuracy plateaued. Training is carried out for 74 epochs.
For initialising the layers, first the shallow network configuration A is trained with all of its layers randomly initialised. Then, to train the deeper architectures, the first four conv. layers and the last three fully-connected layers are initialised with the layers of Net A; the remaining layers are randomly initialised. For random initialisation the weights are sampled from a normal distribution with 0 mean and 0.01 variance. All the biases are initialised to 0.
The training images are isotropically-rescaled, with the smallest side being S (called the training scale). Crops of 224 × 224 are taken from these rescaled images and gives as input to the network.
Testing
Something interesting is done during testing. The test images are isotropically-rescaled, with the smallest side being Q (called the test scale), not necessarily equal to the training scale, S. Then this rescaled image is passed as input to the network without making sure the size matches the “required” input size of 224 × 224. The conv. layers are invariant to the input dimensions. They will work just fine but only give a different sized feature map. The problem arises with the fully-connected layers as these require a pre-defined fixed size dimensional vector as input! To fix this, the fully-connected layers are converted to convolutional layers! The first FC layer becomes a conv. layer with 4096 filters of size 7 × 7 × 512 (this is the dimension of the normal output feature map after the last conv. layer followed by max-pooling). The second FC becomes a conv. layer with 4096 filter each of size 1 × 1 × 4096 and the last FC becomes a conv. layer with 1000 filters of size 1 × 1 × 4096.
Now, if we apply the above network to an input whose size is bigger than 224 × 224, the result will be a class score map with the number of channels (1000) equal to the number of classes and a variable spatial resolution, dependent on the input image size. Finally, to obtain a fixed-size vector of class scores for the image, the class score map is spatially averaged (sum-pooled).
The above is done so that more context can be obtained from the test image, which is otherwise lost due to cropping. Doing this, also makes the network adapt to larger size images and thus making the model more practical in real life use.
Also, not mentioned in the paper but I read somewhere, backward-propagation is faster with fully-connected layers whereas forward-propagation is faster with convolutions!
Conclusion
This paper showed that using a very simple architecture, but by making it deep can boost the accuracy greatly. Also, large (filter size) isn’t always the best, the small things might just give surprisingly better results! One of the biggest shortcoming of this network is the immense number of parameters (approx 1.4 million in VGG19), making this network one of the hardest to train on a low (or even average) spec machine!
Original Paper: Very Deep Convolutional Networks for Large-Scale Image Recognition
Implementation of VGG16: https://github.com/Natsu6767/VGG16-Tensorflow

I have tried to run VGGnet but always getting 10% accuracy. anybody know why is it happing ?
LikeLike
could you do a comparison of VGG, GoogLenet and ResNet please
LikeLike