Variational encoders (VAEs) are generative models, in contrast to typical standard neural networks used for regression or classification tasks. VAEs have diverse applications from generating fake human faces and handwritten digits to producing purely “artificial” music.
This post will explore what a VAE is, the intuition behind it and also the tough looking (but quite simple) mathematics that powers this beast!
But first, let’s look at simple autoencoders in brief.
A Glance at Autoencoders
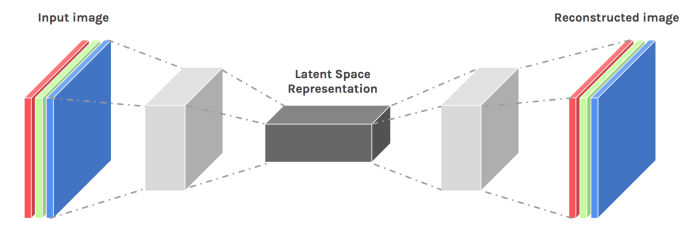
An autoencoder takes some data as input and discovers some latent state representation of the data. The encoder network takes in the input data (such as an image) and outputs a single value for each encoding dimension. The decoder takes this encoding and attempts to recreate the original input. Autoencoders find applications in tasks such as denoising and unsupervised learning but face a fundamental problem when faced with generation.
The latent space to which autoencoders encode the input to may not be continuous. Due to the discontinuity, a point sampled from there and passed to the decoder can generate unrealistic outputs. Autoencoders are only good at generating outputs of data they have already seen but face problems while trying to generate new unseen data.
Variational Autoencoders to the Rescue
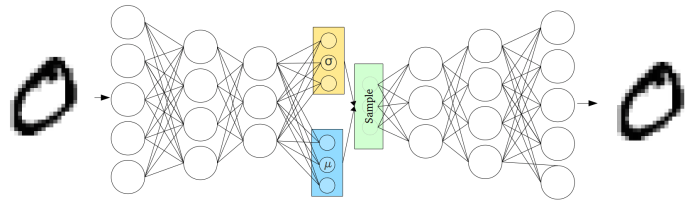
Unlike the normal autoencoders, the encoder of the VAE (called the recognition model) outputs a probability distribution for each latent attribute. For example, assume the distribution is a normal distribution. The output of the recognition model will be two vector: one for the mean and the other for the standard deviation. The mean will control where the encoding of the input should be centered around while the standard deviation will control how much can the encoding vary from the mean. To decode, the values of each latent state is randomly sampled from the corresponding distribution and given as input to the decoder (called the generation model). The decoder then attempts to reconstruct the initial input to the network.
So, how does this help?
Unlike in an encoder which encodes each input as a distinct point and forms distinct clusters in the latent space to encode each type of data (class, etc) with discontinuities between clusters (as doing this will allow the decoder to easily reconstruct the input), the VAE generation model learns to reconstruct not only from the encoded points but also from the area around them. This allows the generation model to generate new data by sampling from an “area” instead of only being able to generate already seen data corresponding to the particular fixed encoded points.
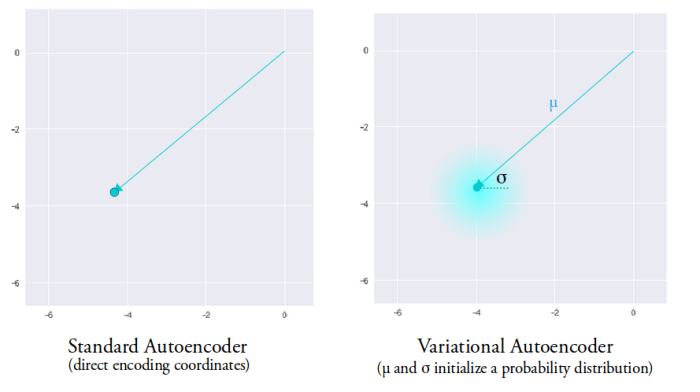
To get even better encodings which help in the generation task, we would like to have overlap between samples of different classes in the latent space as well. This will allow interpolations between classes and hence remove the discontinuity in the latent space. But there is one problem standing in our way. Let’s assume that the encoding distribution is a normal distribution to understand. As there are no limits on the mean, 
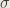
Mathematics Behind VAE
I hope the section above was able to provide you with some basic intuition of what VAEs do. This section will look at the mathematics running in the background.
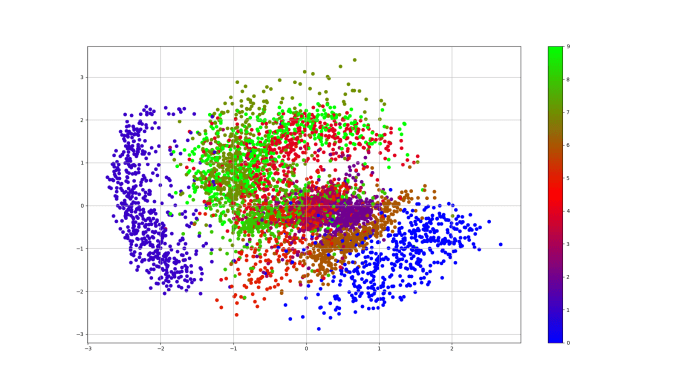
VAEs map the input to a distribution 

- A value
is generated from a prior distribution
.
- A value
.
We can only see x, but we would like to infer the characteristics of z. In other words, we’d like to compute:

But, 

To solve this problem, a recognition model 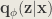
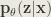

Now, let’s expand the KL Divergence:
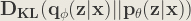

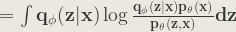
![\mathbf{ = \int q_{\phi }(z|x)[\log p_{\theta }(x) + \log\frac{q_{\phi }(z|x)}{p_{\theta }(z,x)}]dz }](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B+%3D+%5Cint+q_%7B%5Cphi+%7D%28z%7Cx%29%5B%5Clog+p_%7B%5Ctheta+%7D%28x%29+%2B+%5Clog%5Cfrac%7Bq_%7B%5Cphi+%7D%28z%7Cx%29%7D%7Bp_%7B%5Ctheta+%7D%28z%2Cx%29%7D%5Ddz+%7D+&bg=ebe8df&fg=333333&s=1&c=20201002)
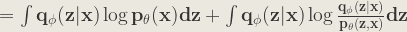
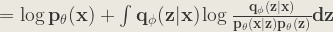
![\mathbf{ = \log p_{\theta }(x) + \int q_{\phi }(z|x)[\log\frac{q_{\phi }(z|x)}{p_{\theta }(z)} - \log p_{\theta }(x|z)]dz }](https://s0.wp.com/latex.php?latex=%5Cmathbf%7B+%3D+%5Clog+p_%7B%5Ctheta+%7D%28x%29+%2B+%5Cint+q_%7B%5Cphi+%7D%28z%7Cx%29%5B%5Clog%5Cfrac%7Bq_%7B%5Cphi+%7D%28z%7Cx%29%7D%7Bp_%7B%5Ctheta+%7D%28z%29%7D+-+%5Clog+p_%7B%5Ctheta+%7D%28x%7Cz%29%5Ddz+%7D+&bg=ebe8df&fg=333333&s=1&c=20201002)

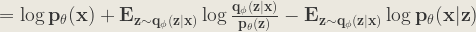
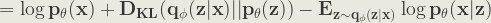

The L.H.S. consists of the terms we want to maximize:
- The log-likelihood of generating real data:
- Negative of the difference between the real and estimated posterior distribution: the
term.
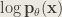
The R.H.S. is called the evidence lower bound (ELBO) as it is always <= 
The loss function will be the negative of the ELBO (as we minimize the loss and ELBO is maximized).
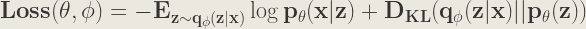
To see how to find the solution of the 
Technical Details for Implementing VAE
This section will be for highlighting some of the technical details of using VAEs in practice. We’ll assume that the prior,
The recognition model is a neural network that will output two vectors; one for the mean and the other for the standard deviation of the multivariate normal distribution of the latent space. One assumption imposed is that the covariance matrix of the multivariate normal distribution only has non-zero values on the diagonal, i.e. it is a diagonal matrix and hence a single vector is sufficient to describe it.
The generation model, also a neural network, will generate a reconstruction by sampling from the defined distribution. However, this sampling process introduces a major problem. Stochastic gradient descent via backpropagation cannot handle such stochastic units within the network! The sampling step blocks gradients from flowing into the recognition model and hence it will not train. To solve this problem, the “reparameterization trick” is used.
The Reparameterization Trick
The random variable 
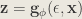


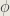

The stochasticity only remains in the random variable 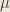
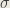
As we have considered the distribution to be a multivariate normal with diagonal covariance structure, the reparameterization trick will give:

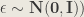
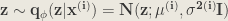
Another small point to take care of is the fact that the network may learn negative values for 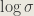
Generating New Data from Variational Autoencoders
By sampling from the latent space and passing this to the generation model, we can generate new unseen data. As we had assumed the prior distribution, 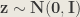
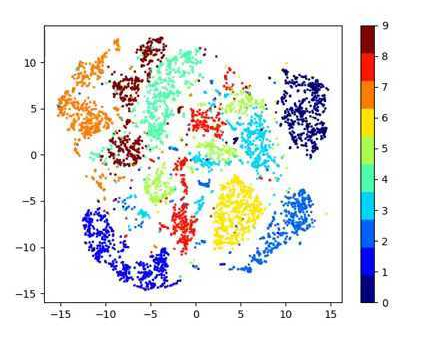
I trained a variational autoencoder on the MNIST dataset for 20 epochs. The code can be found in this GitHub repo. The figure below shows the visualization of the 2D latent manifold. To generate this, a grid of encodings is sampled from the prior and passed as input to the generation model.

The visualization clearly shows how the encoding of the digits vary in the latent space and how different digits merge together (interpolation).
Mohit Jain
References
[1] Kingma, D. P. & Welling, M. (2013). Auto-Encoding Variational Bayes. CoRR, abs/1312.6114.
[2] Carl Doersch. Tutorial on variational autoencoders. arXiv:1606.05908, 2016.
[3] Intuitively Understanding Variational Autoencoders. Towards Data Science medium.
[4] From Autoencoders to Beta-VAE. lilianweng.github.io
[5] Variational autoencoders. jeremyjordan.me
[6] Ali Ghodsi: Deep Learning, Variational Autoencoder (Oct 12 2017)
[7] Variational Autoencoders. Arxiv Insights.
[8] Kullback-Leibler Divergence Explained. Count Bayesie
Appendix
Solution of
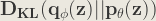
We’ll assume that 

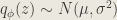

Also, make note of the following properties as these will be used in derivation:
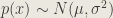



Now, let’s move onto the derivation.
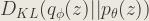

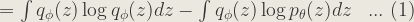
Now, taking the first term of (1):


![= \int q_{\phi}(z)[-\frac{(z - \mu)^{2}}{2\sigma^{2}} - \log(2\pi \sigma ^{2})^\frac{1}{2}]dz](https://s0.wp.com/latex.php?latex=%3D+%5Cint+q_%7B%5Cphi%7D%28z%29%5B-%5Cfrac%7B%28z+-+%5Cmu%29%5E%7B2%7D%7D%7B2%5Csigma%5E%7B2%7D%7D+-+%5Clog%282%5Cpi+%5Csigma+%5E%7B2%7D%29%5E%5Cfrac%7B1%7D%7B2%7D%5Ddz+&bg=ebe8df&fg=333333&s=1&c=20201002)


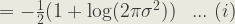
Now, taking the second term of (1):

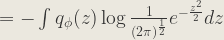
![= -\int q_{\phi}(z)[-\frac{z^{2}}{2} - \frac{1}{2}\log(2\pi)]dz](https://s0.wp.com/latex.php?latex=%3D+-%5Cint+q_%7B%5Cphi%7D%28z%29%5B-%5Cfrac%7Bz%5E%7B2%7D%7D%7B2%7D+-+%5Cfrac%7B1%7D%7B2%7D%5Clog%282%5Cpi%29%5Ddz+&bg=ebe8df&fg=333333&s=1&c=20201002)

![= \frac{1}{2}(\int [(z - \mu)^{2} + 2\mu z - \mu ^{2}]q_{\phi}(z)dz + \log(2\pi).1)](https://s0.wp.com/latex.php?latex=%3D+%5Cfrac%7B1%7D%7B2%7D%28%5Cint+%5B%28z+-+%5Cmu%29%5E%7B2%7D+%2B+2%5Cmu+z+-+%5Cmu+%5E%7B2%7D%5Dq_%7B%5Cphi%7D%28z%29dz+%2B+%5Clog%282%5Cpi%29.1%29+&bg=ebe8df&fg=333333&s=1&c=20201002)



Now, adding (i) and (ii),

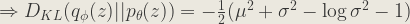
The above derivation for the one dimensional case can easily by extended to the multivariate normal distribution. The expression then becomes:
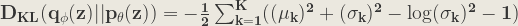
where 


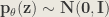
When using a recognition model 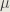



Code for the latent loss in TensorFlow:
#KL Divergence loss term #The recognition model outputs log of the s.d. #Exponentiate this to get actual s.d. self.latent_loss = 0.5 * tf.reduce_sum(tf.square(self.z_mean) + tf.exp(2.0*z_stddev) - 2.0*z_stddev - 1, 1)

I’ve seen about 10 different explanations of the VAE but yours was the first where I understood why they made it generate a mean and a variance. Thank you!
LikeLiked by 1 person
Hi ale,
Thanks for reading. Happy that the article helped you!
LikeLike