I will try to make this post as light on mathematics as is possible, but a complete in depth understanding can only come from understanding the underlying mathematics!
Generative learning algorithms are really beautiful! Like anything they have there advantages and disadvantages. These algorithms are a bit “tough” to understand but comparing them by the “easier” to understand discriminative learning algorithms should make things easier.

Let’s start by talking about discriminative learning algorithms.
Discriminative Learning Algorithms:
A discriminative classifier tries to model by just depending on the observed data. It makes fewer assumptions on the distributions but depends heavily on the quality of the data (Is it representative? Are there a lot of data?). An example is the Logistic Regression.
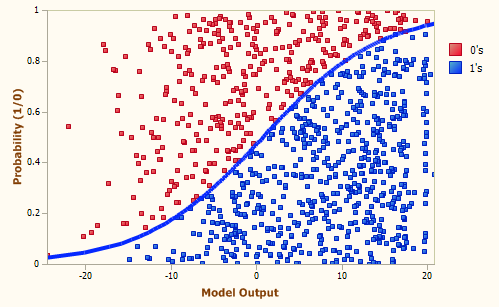
A discriminative model learns the conditional probability distribution: P(y | x) – which should be read as “the probability of y given x“.
To predict the label y from the training example x, the models evaluate:
f(x) = argmax_y P(y | x)
The above equation means: choose the value of y which maximises the conditional probability P(y | x). Or in simpler terms – the above chooses the most likely class y considering x. This can be visualised as the model creating decision boundaries between the classes. To classify a new example the model checks on which side of the decision boundary the example falls on.
Now let’s move onto generative learning algorithms.
Generative Learning Algorithms:
Generative approaches try to build a model of the positives and a model of the negatives. You can think of a model as a “blueprint” for a class. A decision boundary is formed where one model becomes more likely. As these create models of each class they can be used for generation.
To create these models, a generative learning algorithm learns the joint probability distribution P(x, y).
Now time for some maths!
The joint probability can be written as:
P(x, y) = P(x | y) . P(y) ….(i)
Also, using Bayes’ Rule we can write:
P(y | x) = P(x | y) . P(y) / P(x) ….(ii)
Since, to predict a class label y, we are only interested in the arg max , the denominator can be removed from (ii).
Hence to predict the label y from the training example x, generative models evaluate:
f(x) = argmax_y P(y | x) = argmax_y P(x | y) . P(y)
The most important part in the above is P(x | y). This is what allows the model to be generative! P(x | y) means – what x (features) are there given class y. Hence, with the joint probability distribution function (i), given a y, you can calculate (“generate”) its corresponding x. For this reason they are called generative models!
Generative learning algorithms make strong assumptions on the data. To explain this let’s look at a generative learning algorithm called Gaussian Discriminant Analysis (GDA)
Gaussian Discriminant Analysis (GDA):
This model assumes that P(x|y) is distributed according to a multivariate normal distribution.
I won’t go into the maths involved but just note that the multivariate normal distribution in n-dimensions, also called the multi-variate Gaussian distribution, is parameterized by a mean vector μ ∈ Rn and a covariance matrix Σ ∈ Rnxn.
A Gaussian distribution is fit for each class. This allows us to find P(y) and P(x | y). Using this two we can finally find out P(y | x), which is required for prediction.
For a two class dataset, pictorially what the algorithm is doing can be seen as follows:

Shown in the figure are the training set, as well as the contours of the two Gaussian distributions that have been fit to the data for each of the two classes. Also shown in the figure is the straight line giving the decision boundary at which p(y = 1|x) = 0.5. On one side of the boundary, we’ll predict y = 1 to be the most likely outcome, and on the other side, we’ll predict y = 0.
As we now have the Gaussian distribution (model) for each class, we can also generate new samples of the classes. The features, x, for these new samples will be taken from the respective Gaussian distribution (model).
The above should have given you some intuition of how a generative learning algorithm works.
The following discussion will help you see the difference between generative and discriminative learning algorithms much more clearly.
Discussion:
Generative algorithms make a strong assumption on the data. GDA assumes that the data is distributed as multi-variate Gaussian. Naive Bayes (another generative algorithm) assumes that each feature is independent of other features in the data. On the contrary, discriminative algorithms make weak assumptions on the data. Logistic regression assumes that P(y | x) is a logistic function. This is a weaker assumption to that given by GDA because if P(x|y) is multivariate Gaussian then P(y|x) necessarily follows a logistic function. The converse, however, is not true; i.e., P(y|x) being a logistic function does not imply P(x|y) is multivariate Gaussian. (Please carefully note the ordering of x and y in the above probabilities!)
Generative models often outperform discriminative models on smaller datasets because their generative assumptions place some structure on your model that prevents overfitting. For example, let’s consider GDA vs. Logistic Regression. The GDA assumption is of course not always satisfied, so logistic regression will tend to outperform GDA as your dataset grows (since it can capture dependencies that GDA can’t). But when you only have a small dataset, logistic regression might pick up on spurious patterns that don’t really exist, so the GDA acts as a kind of “regularizer” on your model that prevents overfitting.
What this means is that generative models can actually learn the underlying structure of the data if you specify your model correctly and the model actually holds, but discriminative models can outperform them in case your generative assumptions are not satisfied (since discriminative algorithms are less tied to a particular structure, and assumptions are rarely perfectly satisfied anyways!).
There’s a paper by Andrew Ng and Michael Jordan on discriminative vs. generative classifiers that talks about this more.
The crux of the paper is:
- Generative models have higher asymptotic error (as the number of training examples becomes large) as compared to discriminative models.
- Generative models generally approach their asymptotic error much faster than discriminative model.
Asymptotic error is the lowest possible error achievable by the model.
These graphs from the paper help visualise the above two points:

- Plots are of generalisation error vs m (averaged over 1000 random train/test splits). Dashed line is logistic regression (a dicriminative learning algorithm); solid line is naive Bayes (a generative learning algorithm).
As can be seen from the plots, if the amount of training data is less, generative algorithms generally give better results.
One thing to keep in mind is that, neither of the two types of algorithms are superior compared to each other! Both have their use cases.
I hope this post has helped you understand generative learning algorithms and develop an intuition of how these compare to discriminative ones.
If you have any doubts feel free to ask them and if you find any corrections or some problems please feel free to contact me.
Mohit Jain
References:
https://www.youtube.com/watch?v=qRJ3GKMOFrE
https://brilliant.org/wiki/bayes-theorem/
http://www.chioka.in/explain-to-me-generative-classifiers-vs-discriminative-classifiers/
https://stats.stackexchange.com/questions/12421/generative-vs-discriminative
